 Frikipandi – Web de Tecnología – Lo más Friki de la red. Web de Tecnología con las noticias más frikis de Internet. Noticias de gadgets, Hardware, Software, móviles e Internet. Frikipandi
Frikipandi – Web de Tecnología – Lo más Friki de la red. Web de Tecnología con las noticias más frikis de Internet. Noticias de gadgets, Hardware, Software, móviles e Internet. Frikipandi 
Hoy os dejamos un artículo SEO que debes leer. Metehan Yeşilyurt SEO experto:»Desvela las 9 fases del algoritmo de Google Discover» Indispensable para entender como funcia uno de los algoritmos que más guerra nos dan a los SEO.
Metehan Yeşilyurt realizó una investigación excelente en Google Discover. Si te interesa el tráfico de Discover, deberías leer los enlaces al final.
Para una infografía de alta resolución: https://lnkd.in/e-nXmVgv
𝟗 𝐭𝐡𝐢𝐧𝐠𝐬 𝐈 𝐥𝐞𝐚𝐫𝐧𝐞𝐝 𝐚𝐛𝐨𝐮𝐭 𝐆𝐨𝐨𝐠𝐥𝐞 𝐃𝐢𝐬𝐜𝐨𝐯𝐞𝐫 (𝐟𝐫𝐨𝐦 𝐌𝐞𝐭𝐞𝐡𝐚𝐧’𝐬 𝐒𝐃𝐊 𝐭𝐞𝐥𝐞𝐦𝐞𝐭𝐫𝐲 𝐫𝐞𝐬𝐞𝐚𝐫𝐜𝐡)
𝟏. 𝐃𝐢𝐬𝐜𝐨𝐯𝐞𝐫 𝐡𝐚𝐬 𝐚 𝐛𝐢𝐧𝐚𝐫𝐲 “𝐜𝐨𝐥𝐥𝐞𝐜𝐭𝐢𝐨𝐧 𝐠𝐚𝐭𝐞”
Antes de cualquier coincidencia o clasificación de intereses, hay un interruptor de encendido/apagado: si la colección está oculta, estás fuera. Ningún título que diga «esfuérzate más» solucionará eso.
𝟐. 𝐎𝐆 𝐭𝐚𝐠𝐬 𝐚𝐫𝐞 𝐧𝐨𝐭 “𝐬𝐨𝐜𝐢𝐚𝐥 𝐦𝐞𝐭𝐚”, 𝐭𝐡𝐞𝐲’𝐫𝐞 𝐟𝐞𝐞𝐝 𝐦𝐞𝐭𝐚
El SDK analiza un conjunto estricto de etiquetas. Si tu imagen o título OG se rompe, tu tarjeta Discover puede romperse con él.
¿Tienes og:title? Prueba con el título de Twitter y luego con el título HTML.¿No tienes og:image? Prueba con la URL segura, la imagen de Twitter y más.Esto es «lógica de renderizado», no teoría SEO.
3. Clasificación de contenido
Clasifica el contenido en actualizado o contenido evergreeen
𝟒.𝐄𝐧𝐭𝐢𝐭𝐢𝐞𝐬 𝐚𝐫𝐞 𝐭𝐡𝐞 𝐦𝐚𝐭𝐜𝐡𝐦𝐚𝐤𝐞𝐫
se asigna a los ID del Gráfico de Conocimiento y luego se relaciona con el gráfico de intereses del usuario. Por eso los titulares vagos tienen problemas: no le dan al sistema nada con qué comparar.
𝟓. 𝐑𝐚𝐧𝐤𝐢𝐧𝐠 𝐢𝐬 𝐩𝐂𝐓𝐑, 𝐛𝐮𝐭 𝐭𝐡𝐞 𝐦𝐨𝐝𝐞𝐥 𝐢𝐬 𝐬𝐞𝐫𝐯𝐞𝐫-𝐬𝐢𝐝𝐞
El cliente puede dar pistas sobre las señales (frescura, calidad de la imagen, participación histórica), pero la puntuación real ocurre del lado de Google.
𝟔. 𝐅𝐫𝐞𝐬𝐡𝐧𝐞𝐬𝐬 𝐡𝐚𝐬 𝐛𝐮𝐜𝐤𝐞𝐭𝐬, 𝐢𝐭’𝐬 𝐧𝐨𝐭 𝐣𝐮𝐬𝐭 “𝐟𝐞𝐞𝐥𝐬 𝐟𝐫𝐞𝐬𝐡”
Hay ventanas de tiempo explícitas. Después de la primera semana, estás luchando contra el deterioro a menos que tu contenido se trate como perenne.
𝟕. 𝐃𝐞𝐥𝐢𝐯𝐞𝐫𝐲 𝐢𝐬 𝐚 𝐥𝐢𝐯𝐞 𝐬𝐭𝐫𝐞𝐚𝐦, 𝐧𝐨𝐭 𝐚 𝐬𝐭𝐚𝐭𝐢𝐜𝐚 𝐥𝐢𝐬𝐭
Entre la transmisión, la sincronización en segundo plano, el envío de balizas y el almacenamiento en caché, su tarjeta puede aparecer, moverse o desaparecer sin una «actualización».
𝟖. 𝐔𝐬𝐞𝐫 𝐟𝐞𝐞𝐝𝐛𝐚𝐜𝐢𝐨 𝐞𝐬 𝐚𝐥𝐢𝐬𝐭𝐨 𝐝𝐞 𝐟𝐢𝐫𝐬𝐭𝐭𝐨 𝐜𝐥𝐚𝐬𝐭𝐨𝐬 𝐬𝐢𝐠𝐧𝐚𝐥𝐞𝐬 𝐝𝐞 𝐥𝐚𝐬 𝐜𝐨𝐦𝐩𝐚𝐫𝐚 ….
Los despidos, los seguidores, los guardados y el tiempo de interacción alimentan el ciclo. Discover aprende constantemente lo que cada usuario quiere y lo que no.
𝟗. 𝐓𝐡𝐢𝐬 𝐦𝐞𝐚𝐧𝐬 “𝐃𝐢𝐬𝐜𝐨𝐯𝐞𝐫 𝐝𝐫𝐨𝐩𝐬” 𝐧𝐞𝐞𝐝 𝐚 𝐧𝐞𝐰 𝐝𝐢𝐚𝐠𝐧𝐨𝐬𝐢𝐬
No todas las caídas son “clasificación”. A veces es:
• un problema de renderizado (OG/imagen)
• un problema de puerta/filtro (colección)
• o volatilidad normal del experimento
El gráfico a continuación es mi intenta de hacer que este pipeline sea visual para los editores, basado en el análisis de Metehan. Puedes leer los artículos completos en:> https://lnkd.in/eXzuwNw9 > https://lnkd.in/ebhtTS3n > https://lnkd.in/e_tvr8H5
pero lo dejamos aquí traducido para que como buen SEO puedas sacar las conclusiones para tu medio
Metehan Yeşilyurt ha sacado el código del SDK de Google Discover para que usted no tenga que hacerlo y lo ha analizado: clústeres, clasificadores, etiquetas OG, NAIADES… (Herramienta pCTR gratuita incluida)
La mayoría de los consejos de Discover son:
publica contenido de calidad, usa imágenes grandes, publica con constancia y deja que el algoritmo te encuentre. No está mal. Como siempre digo el contenido es el Rey y es lo básico para un redactor de un medio digital pero simplemente es incompleto si no tienes experiencia con el algoritmo de Discover. Juan Cascón Subdirector técnico de Abside Media y SEO de COPE dío una claves de Discover en una congreso para la COFER que debemos tener en cuenta siempre
Google Discover ofrece contenido a cientos de millones de personas a diario, y casi nadie en el mundo del SEO ha analizado en detalle cómo funciona realmente desde el lado del cliente. No a través de especulaciones, sino a través del propio SDK.
A eso le dediqué tiempo. Revisé la telemetría observable, las convenciones de nomenclatura de eventos y el estado del lado del cliente que el propio código de Google expone durante la operación normal de Discover. Cada hallazgo que compartiré se remonta a una cadena, constante o valor de configuración específico. Cuando algo es una inferencia, lo digo.
Piensa en ello es como leer la etiqueta nutricional de un alimento. No puedes ver el interior de la fábrica, pero la etiqueta te dice mucho sobre su contenido. Pues hay cosas para sacar buenas conclusiones.

El hallazgo que replanteó todo para Metehan Yeşilyurt
El flujo de contenido de Discover tiene 9 etapas (identifiqué 9). Lo que no esperaba era el orden. ¿Por qué 9? En realidad, estas son solo arquitecturas del lado del cliente.
El filtro a nivel de colección se ejecuta en la etapa 4. La correspondencia de intereses se ejecuta en la etapa 6. El modelo pCTR se ejecuta en la etapa 7.
El bloqueo se activa cuando un usuario pulsa «No mostrar contenido de [Editor]». Un artículo. Una acción del usuario. Todo el dominio se suprime.
Y aquí está la asimetría que importa: no hay un equivalente observable de un impulso general. La superficie de penalización es mayor que la de recompensa. No se trata de un juicio editorial mío. Es simplemente lo que el sistema revela.
Lo que realmente consume el modelo pCTR
Se menciona la existencia de un modelo de tasa de clics predicha en Discover. Lo que se desconoce es qué datos lo alimentan. Según la telemetría, estos datos incluyen el texto del título de og:title, indicadores de calidad de la imagen, como los umbrales de ancho y alto, la frescura medida en segundos, el CTR histórico derivado de los recuentos de clics y visualizaciones por URL, y las tasas de éxito de carga de imágenes.
El significado práctico de esto: og:title no es solo una etiqueta para mostrar. Es una entrada del modelo. Esta distinción es importante. Un título se evalúa, no solo se muestra.
Al mismo tiempo, la presencia del CTR histórico como señal de retroalimentación es en sí misma una forma de justicia. Los títulos engañosos que generan clics pero no interacción deberían corregirse con el tiempo, ya que los clics iniciales altos seguidos de rebotes rápidos degradan las puntuaciones futuras de pCTR.
Panel de control aquí: https://metehan.ai/discover.html
Herramienta gratuita experimental pCTR aquí: https://pctr-discover.pages.dev
Es muy interesante la fórmula que calcula dando los siguiente valores y donde deben poner el foco la densidad de entidades que funcionen en Discover un 22% Anda que no he insistido esto en la redacción. Le sigue la claridad del tema contenido bien explicado y estructurado con negritas y ladillos La siguen con un 18% el valor informativo con una buena entradilla, introducción, desarrollo y conclusión. Que responda a las preguntas de los usuarios. Ahora empieza algunas cosas curiosas la señal de frescura vale un 12%por eso caen las noticias en el tiempo. Si se te va de Discover debes publicar otra noticia. Le sigue la profundidad con un 10%. La longitud y la originalidad son importantes. Luego con un 8% esta el formato de título si tienes un nombre , una actividad o profesión y alguna entidad en el titular entonces tienes un buen titular pero debe también llamar la atención al usuario. Tienes también un 8% de autoridad natural si publicas en un medio que este en el publisher center y tienes a un experto en el tema todo ayuda y por último una promesa visual con un 6% la calidad de la imagen que llame la atención y tenga como poco 1280px de ancho.

Los intervalos de frescura
Discover tiene tres intervalos de tiempo con nombre y una fase de decaimiento continuo (identificada hasta ahora en eventos de cliente, ¡quizás haya más!). El contenido con una antigüedad de 1 a 7 días tiene la mayor ponderación de frescura. El contenido con una antigüedad de 8 a 14 días se reduce a media. El contenido con una antigüedad de 15 a 30 días se reduce a baja. Después de 30 días, la obsolescencia se registra en horas y se decae continuamente. ¡Discover utiliza milisegundos! FCFS.
La primera semana es cuando el contenido alcanza su mejor momento. No se trata de una guía flexible. Los contenedores están codificados en el sistema.
Las 6 etiquetas OG que realmente importan
Los editores a menudo se preguntan qué metaetiquetas analiza Discover. El SDK ofrece una respuesta clara: exactamente seis. og:image y og:title son obligatorios. Sin una imagen, no se renderiza ninguna tarjeta. Punto. El ancho mínimo para una tarjeta de héroe grande es de 1200 px. Las imágenes más pequeñas generan una tarjeta miniatura, que suele generar menos interacción.
Se recomiendan las otras cuatro etiquetas: og:site_name, og:locale, og:image:secure_url y article:content_tier. Estas afectan la visualización de la atribución, la coincidencia de configuración regional, la preferencia HTTPS y la clasificación del contenido por niveles.
NAIADES y la pila de personalización de la que nunca has oído hablar
La personalización de Discover se basa en cuatro capas. Las dos más externas son infraestructura compartida de Google: el gráfico de intereses Geller/AIP, utilizado en el Asistente y la Búsqueda, y un sistema llamado NAIADES, un sistema de personalización para todo Google con 18 subtipos de contenido.
Ya lo captó aquí con el ejemplo de Cambridge: https://metehan.ai/blog/image-to-seo-i-built-an-ai-tool-to-decode-google-discover-heres-what-it-found/

Lápidas
Cuando un usuario descarta contenido, se crean tres registros: un ID de superposición de descarte, una actualización del estado del filtro y un registro de descarte. Este registro es permanente por contenido. El contenido descartado no vuelve a aparecer. Nunca. El registro no caduca.
150 experimentos A/B a la vez
Durante una sola sesión observada, aproximadamente 150 ID de experimentos A/B del servidor estuvieron activos simultáneamente. Dos usuarios con intereses y comportamientos idénticos pueden ver feeds significativamente diferentes, basándose únicamente en la asignación de segmentos de experimentos. Por eso, Discover puede resultar inconsistente incluso cuando el contenido y los patrones de publicación no han cambiado.
El panorama completo
Esta publicación cubre los aspectos más destacados. El panel técnico completo incluye constantes de eventos, 56 contadores de telemetría, 18 subtipos de NAIADES, 13 tipos de clústeres, 51 indicadores de características en tiempo de ejecución y 41 hallazgos verificados individualmente.
Panel de control aquí: https://metehan.ai/discover.html
Herramienta gratuita experimental pCTR aquí: https://pctr-discover.pages.dev
Si has estado tratando a Discover como una caja negra, espero que esto al menos le proporcione algunas pistas
Google Discover ofrece contenido a cientos de millones de usuarios a diario, pero su funcionamiento interno sigue siendo en gran medida opaco. La mayoría de las recomendaciones de SEO sobre Discover provienen de la propia documentación de Google o de observaciones puntuales de los editores. En esta publicación, quiero compartir una perspectiva diferente: lo que podemos aprender al examinar la telemetría observable, las convenciones de nomenclatura de eventos y el estado del cliente de la aplicación de Google.
Todo lo descrito a continuación refleja lo que el código del lado del cliente revela en un momento específico y ha sacado Metehan Yeşilyurt. Esto es Google. Pueden cambiar cualquiera de estos sistemas (señales de clasificación, etapas del pipeline, contadores de telemetría y marcadores de características) en el servidor en cualquier momento, sin necesidad de actualizar al cliente. Lo que lee aquí es una instantánea, no un modelo definitivo. Considérelo como una perspectiva de cómo funcionan estos sistemas hoy, no como una garantía de cómo funcionarán mañana.
Cuando algo es una inferencia en lugar de una observación directa, lo digo. Necesitaba manejar una gran cantidad de datos y eliminé muchas partes.
Piense en esto como leer la etiqueta nutricional de un alimento envasado. No se puede ver la fábrica, pero la etiqueta revela bastante información sobre su contenido.
El canal de contenido#
El flujo de contenido de Discover https://metehan.ai/blog/google-discover-architecture/#the-content-pipeline se puede asignar a varias etapas observables, cada una de las cuales deja rastros de telemetría distintos:
- Ingesta de contenido: Google rastrea e indexa el contenido. La extracción de entidades asigna MIDs del Gráfico de Conocimiento (
/m/xxxxx) o (/g/xxxxx) a los temas reconocidos. - Análisis de datos estructurados y Open Graph: El analizador del lado del cliente extrae los metadatos de la página con un orden de prioridad definido: primero se verifica JSON-LD de Schema.org , luego las etiquetas Open Graph, luego las etiquetas de Twitter Card y finalmente las metaetiquetas HTML genéricas. Esta es una cadena de respaldo codificada, no una preferencia. Si JSON-LD contiene el campo, nunca se accede a las etiquetas OG para ese campo.
- Clasificación de contenido: el contenido se asigna a tipos de clúster y se clasifica para la jerarquía de feeds.
- Filtrado de contenido : El sistema opera con dos niveles de filtrado independientes:
filter_collection_status(nivel de editor/dominio) yfilter_entity_status(nivel de URL única). Estos se registran como métricas de streaming específicas de Discover en/client_streamz/android_gsa/discover/app_content/. - Coincidencia de intereses del usuario: los MID de entidades de contenido se comparan con el perfil de intereses del usuario a través del sistema de personalización NAIADES (subtipos verificados a continuación).
- Clasificación (del lado del servidor): La clasificación se realiza del lado del servidor. El código del lado del cliente revela qué datos se empaquetan y se envían al servidor, pero los modelos de clasificación reales no son observables desde el cliente.
- Ensamblaje de feeds: el contenido se organiza y se envía al dispositivo a través de transmisión gRPC, sincronización de WorkManager en segundo plano, envío de balizas o caché.
- Bucle de retroalimentación: Las interacciones del usuario (descartes, seguimientos, guardados) retroalimentan la personalización. El contenido descartado se elimina permanentemente.
Lo destacable aquí es el orden . El filtro a nivel de colección se ejecuta antes de la coincidencia de intereses y la clasificación. Esto significa que un editor bloqueado a nivel de colección ni siquiera llega a la etapa de clasificación, independientemente de la relevancia de su contenido para un usuario.
Datos estructurados y Open Graph: qué analiza realmente el código#
Los editores a menudo se preguntan qué metaetiquetas utiliza realmente Discover. La clase analizadora descompilada ( dkpg.java, autodenominada SchemaOrg{parsedMetatags, jsonLdScripts}) revela las etiquetas exactas y su orden de prioridad.
El hallazgo crítico: Los datos estructurados JSON-LD de Schema.org se verifican primero para el título, el autor y la editorial, no para las etiquetas Open Graph. Las etiquetas OG son la alternativa. Esto está codificado en la lógica de la cadena de respaldo.
Cadenas de respaldo verificadas (desde java files)#
Título:
- Datos estructurados de Schema.org (
TEXT_TYPE_TITLE) og:title(víapropertyatributo)twitter:title(víanameatributo)title(atributo genériconame)
Autor:
- Datos estructurados de Schema.org (
TEXT_TYPE_AUTHOR) author(víanameatributo)
Editor:
- Datos estructurados de Schema.org (
TEXT_TYPE_PUBLISHER) og:site_name(víapropertyatributo)
Imagen:
og:image(víapropertyatributo)twitter:image(víanameatributo)og:image:secure_url(víapropertyatributo)twitter:image:src(víanameatributo)image(atributo genériconame)
Idioma:
- Detección del idioma principal (basada en la ejecución)
og:locale(víapropertyatributo)inLanguage(JSON-LD de Schema.org)- Respaldo codificado de forma rígida
"en"(condicional en la bandera de configuración del servidor)
Clasificación de muros de pago (de dkri.java:173-176, dkqd.java)#
El sistema verifica el estado del muro de pago en este orden exacto:
- Primero:
isAccessibleForFree(Schema.org JSON-LD booleano) — valor predeterminadotruesi está ausente - Entonces:
article:content_tierlos valores reconocidos son exactamente tres cadenas:"free"el valor predeterminado esperado"metered"contabilizado como de pago"locked"contabilizado como de pago
article:content_tierSi se encuentran varios valores en la misma página, el código registra una advertencia "More than one content tier found"(código de evento 38468). Use solo un valor.
Bloqueo de metaetiquetas (desde dkri.java:304-416)#
Dos metaetiquetas detienen el proceso por completo con una excepción ( dkma):
nopagereadalouddesencadenantesDISALLOWED_FOR_READOUTnotranslatedesencadenantesDISALLOWED_FOR_TRANSLATION
Cuando se detecta como metaetiqueta, el sistema genera un error y detiene el procesamiento de esa página. Si su CMS o plugin de traducción la inyecta notranslatecomo metaetiqueta, es posible que su contenido no entre en este proceso de análisis.
Reescritura de JSON/OG en acción#
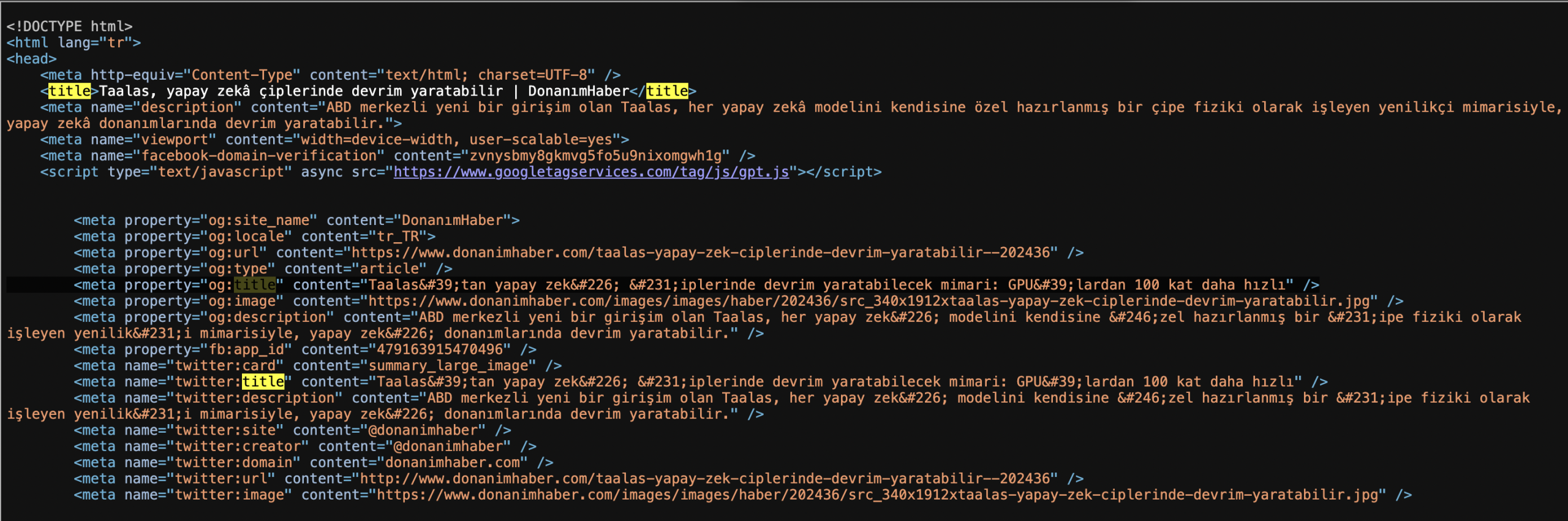
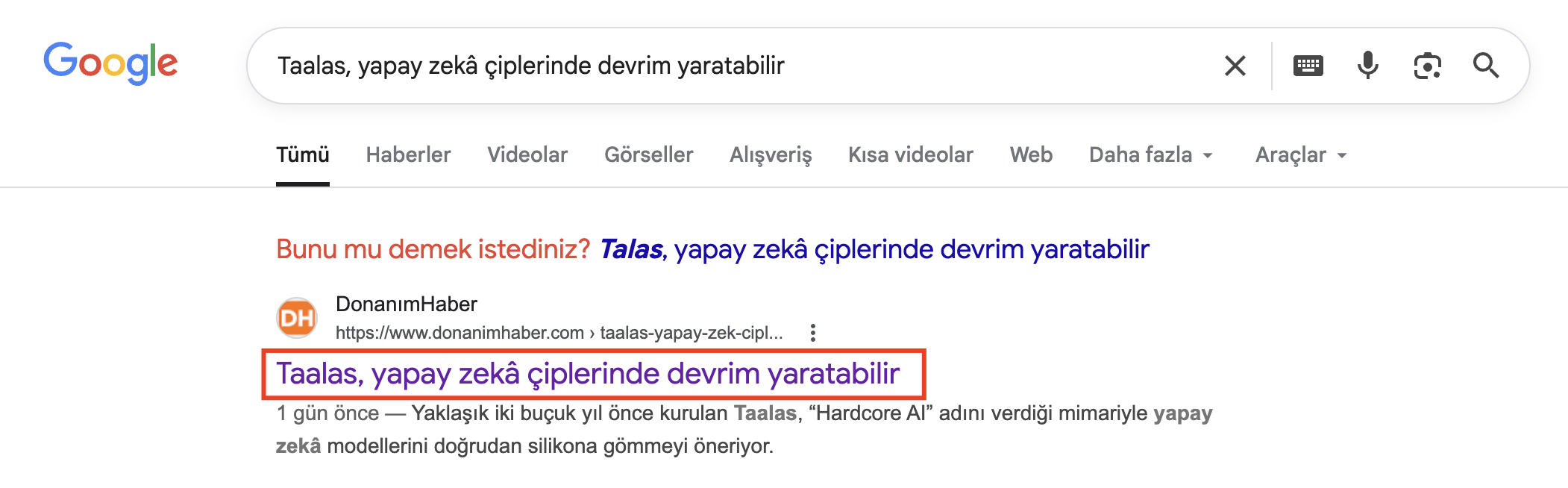
Ahora veamos en Discover a continuación.
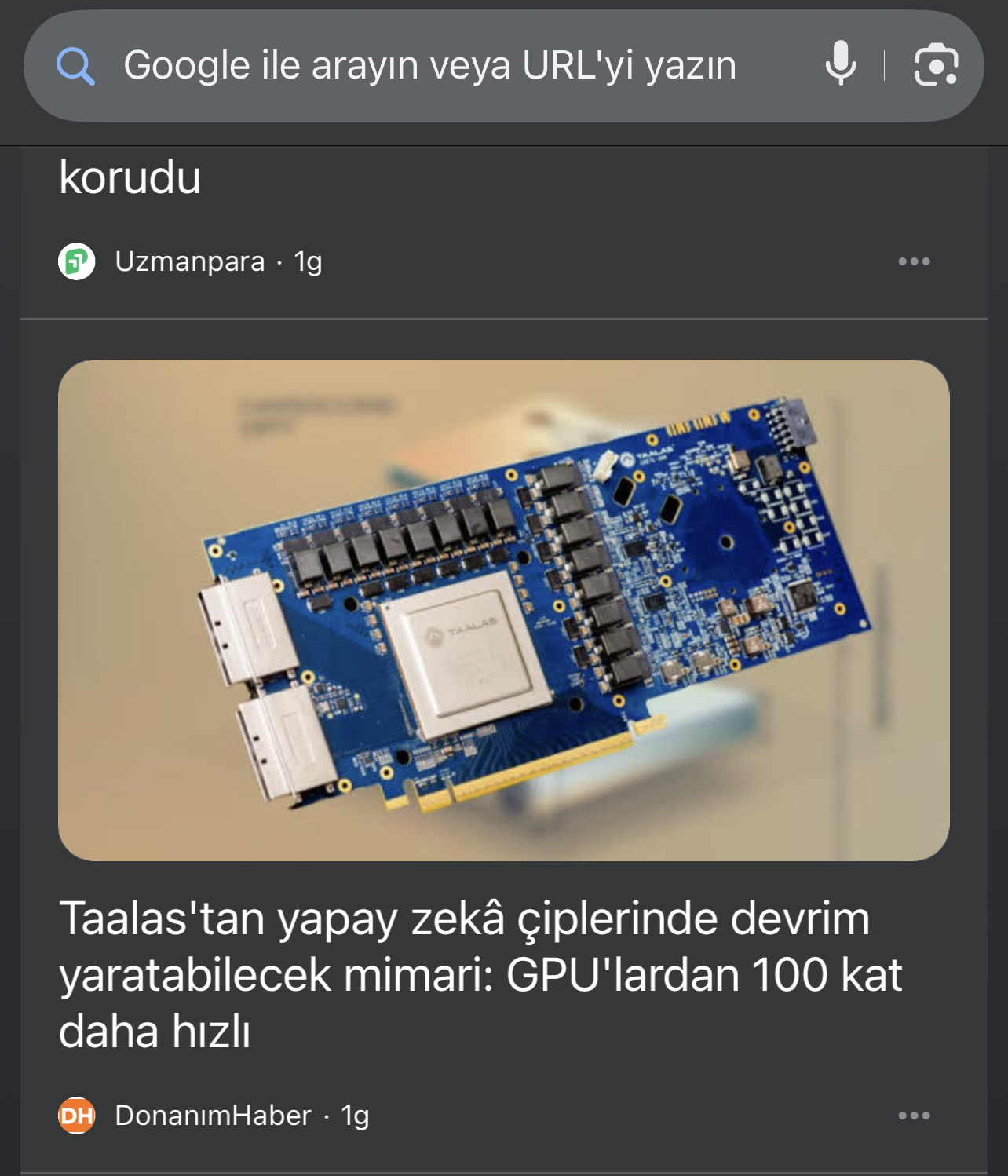
Y este es el enlace de la imagen: https://www.donanimhaber.com/images/images/haber/202436/src_340x1912xtaalas-yapay-zek-ciplerinde-devrim-yaratabilir.jpg
Este enlace JPG se coloca solo en las etiquetas og:image y twitter:image, no en schema.org (¿Está comprobado? No, la otra imagen tiene 1400x788px de ancho en la etiqueta schema, es Google, puedes decidirlo).
Filtrado de contenido: la arquitectura de dos niveles#
El filtrado de contenido de Discover opera en múltiples niveles, cada uno rastreado por su propia métrica streamz específica de Discover, las identificadas se encuentran a continuación:
- Nivel de colección (
/client_streamz/android_gsa/discover/app_content/filter_collection_status): bloquea el contenido de un editor o dominio. Parametrizado porreason. - Nivel de entidad (
/client_streamz/android_gsa/discover/app_content/filter_entity_status): bloquea una única URL. Parametrizado porreason.
Cuando un usuario selecciona «No mostrar contenido de [Editorial]» en el menú de tarjetas, se activa el filtro a nivel de colección. Un solo artículo que genera suficientes comentarios negativos puede suprimir una publicación completa. Esta acción se aplica a todo el contenido de ese dominio, no solo al artículo que la activó. El algoritmo de supresión puede ampliar el filtro a nivel de editorial.
Advertencia importante: Estos son contadores de telemetría del lado del cliente. Confirman la existencia y el seguimiento de los mecanismos de filtrado, pero los umbrales exactos del servidor, los mecanismos de recuperación y cómo los valores de «razón» se asignan a las acciones del usuario no son observables desde el cliente. Google puede cambiar estas configuraciones en cualquier momento sin necesidad de actualizar el cliente.
Lápida de contenido (de bska.java)#
El contenido descartado se registra permanentemente con un tombstonedcampo booleano en el objeto de estado del contenido. El estado del contenido también registra stallState( lastKnownStateINSERTO/ELIMINADO/DESCONOCIDO) y purged, creando un registro completo del ciclo de vida. El contenido descartado no reaparece.
El sistema de personalización NAIADES (desde fiqc.java)#
El código revela un sistema de personalización llamado NAIADES con múltiples subtipos de contenido, todos confirmados como valores de enumeración:
| Subtipo | Valor de enumeración | Lo que sugiere |
|---|---|---|
SUBTYPE_PERSONAL_UPDATE_MID_BASED_NAIADES | 793 | Personalización basada en gráficos de entidad/conocimiento |
SUBTYPE_PERSONAL_UPDATE_QUERY_BASED_NAIADES | 792 | Personalización basada en consultas de búsqueda |
SUBTYPE_PERSONAL_UPDATE_QUERY_BASED_NAIADES_PERSISTENT_LOGGING | 805 | Lo mismo ocurre con el registro persistente |
SUBTYPE_PERSONAL_UPDATE_RECALL_BOOST | 797 | Aumenta la prioridad de recuperación del grupo de candidatos |
SUBTYPE_PERSONAL_UPDATE_WPAS | 800 | Señal de artículos del editor web |
SUBTYPE_PERSONAL_UPDATE_WPAS_PERSISTENT_LOGGING | 811 | Lo mismo ocurre con el registro persistente |
SUBTYPE_PERSONAL_UPDATE_AIM_THREAD_NAIADES | 856 | AIM (Modo AI) basado en subprocesos |
WPAS(Señal de artículos de editores web) probablemente corresponde al registro en el Centro de editores de Google Noticias, lo que significa que el contenido de los editores registrados recibe una clasificación distinta en el proceso de personalización. RECALL_BOOSTEsto puede sugerir una mayor prioridad de recuperación del grupo de candidatos, lo que mejora el contenido durante la recuperación, antes de la clasificación. (No podemos ver la configuración del servidor, por favor, preste atención).
Advertencia: Estos son nombres de enumeración en un sistema de clasificación de subtipos de contenido. Confirman la existencia de las categorías, pero la importancia de cada subtipo en la clasificación es una decisión del servidor que no podemos observar.
Supresión y experimentos contrafácticos#
Discover ejecuta experimentos contrafácticos. El código confirma:
SHOW_SKIPPED_DUE_TO_COUNTERFACTUAL(defevu.java, valor de enumeración 16) — contenido retenido para pruebas A/BVISIBILITY_REPRESSED_COUNTERFACTUAL(deeyxv.java) — un estado de registro de elementos visuales utilizado en toda la aplicación de Google (no específico de Discover) que marca los elementos suprimidos deliberadamente para la medición del experimentobackground_refresh_rug_pull_count(debupa.java, bajo/client_streamz/android_gsa/discover/) un contador específico de Discover que rastrea casos en los que el contenido se envió al feed y luego se eliminó durante una actualización en segundo plano. 100% verificado
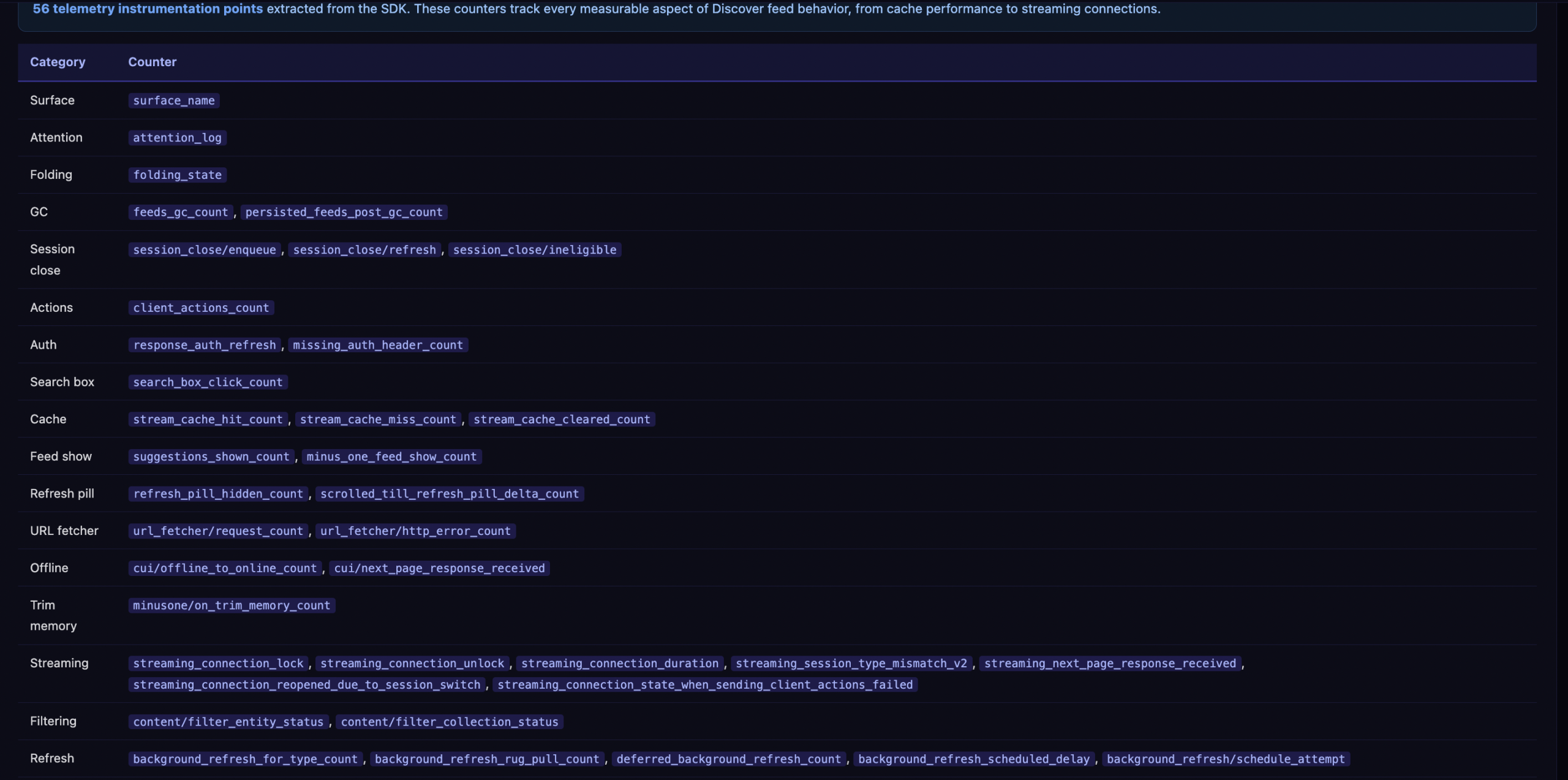
El contador de «retiradas de alfombra» es especialmente destacable. Registra los casos en los que se envió contenido al feed y luego se eliminó retroactivamente. Esto significa que Discover puede retirar contenido que ya estaba en el feed, no solo filtrarlo antes de mostrarlo.
El sistema Beacon Push#
La mayor parte del contenido de Discover llega mediante solicitudes de feed basadas en pull, pero también existe un canal push. El sistema Beacon permite que los servidores de Google envíen contenido de forma proactiva al dispositivo del usuario.
A partir del código descompilado ( bqmt.java), Beacon actualmente maneja exactamente dos tipos de contenido :
- Resultados deportivos (
SportsScoreAmbientDataDocument) ordinal 0 - Resumen de inversiones/finanzas (
InvestmentRecapAmbientDataDocument) ordinal 1 - Cualquier otra cosa se desencadena
"Unsupported BeaconContent type: %s"y se rechaza.
Beacon tiene sus propias métricas (desde bupa.java):
/client_streamz/android_gsa/discover/beacon/incoming_sports_notifications_count
/client_streamz/android_gsa/discover/beacon/donated_sports_documents_count
/client_streamz/android_gsa/discover/beacon/dropped_sports_notifications_count
/client_streamz/android_gsa/discover/beacon/appsearch_cleared_countEl contenido deportivo cuenta con más de 10 tipos de notificaciones dedicadas (desde fkld.java): SPORTS_AWARENESS_NOTIF, SPORTS_GAME_CRICKET_MILESTONE_NOTIF, SPORTS_BREAKING_NEWS_NOTIF, SPORTS_LIVE_ACTIVITY_NOTIF, SPORTS_PREGAME_ANALYSIS_AIM_NOTIF, SPORTS_LEAGUE_INSIGHTS_AIM_NOTIF, SPORTS_STANDINGS_NOTIF, y más. Las noticias generales de última hora solo tienen una: BREAKING_NEWS_NOTIF. La inversión estructural en infraestructura de notificaciones deportivas es significativamente mayor. Es posible que comparta una infraestructura muy similar con Google Noticias. // Esta sección parece dinámica, por lo que puede cambiar en cualquier momento.
Intervalos de frescura#
El código contiene una lógica de clasificación basada en el tiempo (de bemp.java:215):
days < 1 → "0_DAYS"
days < 8 → "1_TO_7_DAYS"
days < 15 → "8_TO_14_DAYS"
days < 31 → "15_TO_30_DAYS"
days < 61 → "31_TO_60_DAYS"
days >= 61 → "TAIL"Corrección importante: En el código descompilado, esta lógica de clasificación aparece en un contexto de configuración de gestos ( GestureSettingsPreferenceFragment), no en una clase específica de Discover. Los nombres de los depósitos y los intervalos de tiempo se confirman como cadenas exactas, pero su conexión directa con la puntuación de frescura del contenido de Discover no se puede verificar únicamente desde el cliente. El patrón de clasificación es coherente con la forma en que Google suele gestionar la antigüedad del contenido, pero no puedo demostrar que estos depósitos específicos se utilicen para la clasificación del feed de Discover.
13 tipos de clústeres#
Cada tarjeta del feed de Discover pertenece a un clúster. Se pueden observar los siguientes nombres de tipo de clúster:
neonclusterel grupo de contenido principalgeotargetingstorieshistorias basadas en la ubicacióndeeptrendsydeeptrendsfablenarrativas de temas de tendenciafreshvideoscontenido de vídeo recientemustntmisscontenido prioritario/de lectura obligadanewsstoriesheadlinesnoticias de última horahomestackTarjetas de widgets (clima, resultados deportivos)garamondrelatedarticlegroupinggrupos de artículos relacionadostrendingugccontenido de tendencia generado por el usuariosigninlureindicaciones de inicio de sesióniospromopromoción multiplataformamoonstoneun clúster con nombre de código interno
mustntmisssugiere que hay una cola prioritaria de contenido que el sistema considera esencial mostrar. garamondrelatedarticlegroupingIndica que el sistema puede crear agrupaciones de artículos relacionados (combinando artículos separados bajo un encabezado de tema compartido).
Entrega de feeds en tiempo real#
Discover no se limita a obtener una lista estática de tarjetas. El código revela una arquitectura de conexión gRPC persistente con puntos finales de servicio distintos (verificado desde [Aquí falta información ehdf.java]):
google.internal.discover.discofeed.feedrenderer.v1.DiscoverFeedRendereralimentación estándar conQueryInteractiveFeedyQueryNextPagegoogle.internal.discover.discofeed.streamingfeedrenderer.v1.DiscoverStreamingFeedRenderervariante de streaming conQueryStreamingFeedgoogle.internal.discover.discofeed.actions.v1.DiscoverActionsUploadActionsyBackgroundUploadActionsgoogle.internal.discover.discofeed.reactions.v1.DiscoverReactionsListReactionsgoogle.internal.discover.discofeed.recommendations.v1.StoryRecommendationsgoogle.internal.discover.discofeed.homestack.v1.DiscoverHomestackFeedRenderer
Lo que esto significa para los editores: su contenido no espera a que el usuario lo actualice. El renderizador del feed de streaming mantiene una conexión en vivo. El servidor puede inyectar nuevas tarjetas, reordenar las existentes o eliminar contenido obsoleto a mitad de la sesión. El feed es una transmisión en vivo, no una instantánea.
¿Qué significa esto para los editores o SEO de lo smedios#
Permítanme aclarar qué es y qué no es este análisis. Se trata de un conjunto de observaciones sobre cómo se instrumentan los sistemas del lado del cliente de la aplicación de Google. No se trata de ingeniería inversa de los algoritmos de clasificación del lado del servidor, que permanecen en los servidores de Google y no son directamente observables.
Dicho esto, surgen algunas observaciones prácticas:
- JSON-LD de Schema.org tiene prioridad sobre las etiquetas OG. El analizador analiza primero los datos estructurados para identificar el título, el autor y la editorial. Las etiquetas OG son la alternativa. Si solo implementa og:tags sin marcado JSON-LD, se basa en la segunda opción.
- Las imágenes son esenciales. La cadena de imágenes de respaldo tiene cinco niveles de profundidad: el sistema se esfuerza por encontrar una imagen. Usa imágenes de al menos 1200 píxeles de ancho para que la tarjeta de héroe sea válida.
og:titleSe empaqueta y se envía a los servidores de Google como parte de la carga útil ContentMetadata. Es plausible que se trate de una entrada de clasificación directa, pero no se ha confirmado únicamente mediante la observación del lado del cliente. En cualquier caso, forma parte de los datos que fundamentan las decisiones del lado del servidor.- El bloqueo a nivel de colección se registra como una métrica independiente. El
filter_collection_statuscontador confirma la existencia de este mecanismo a nivel de editor/dominio. Sin embargo, solo podemos observar el contador de telemetría, no los umbrales del servidor ni los mecanismos de recuperación. Google puede modificarlos en cualquier momento. - El registro en el Centro de Publicaciones genera una señal distintiva. El
WPASsubtipo (Señal de Artículos de Publicaciones Web) implica que las publicaciones registradas reciben un tratamiento de clasificación diferente en el sistema de personalización NAIADES. article:content_tierImporta. El analizador reconoce explícitamentefree,meteredylocked. Use solo un valor; varios valores activan una advertencia.notranslateLasnopagereadaloudmetaetiquetas pueden detener el proceso de análisis. Si tu CMS las inyecta, debes realizar experimentos y filtrar el tráfico de Discover.- Los despidos de usuarios son permanentes. El contenido se elimina y no vuelve a aparecer.
- Los editores deportivos tienen una ventaja estructural en el flujo de notificaciones push. Más de 10 tipos de notificaciones dedicados frente a uno para noticias generales de última hora. El cliente confirma que no podemos ver la configuración del servidor.
MIS correcciones y advertencias#
Durante la verificación de datos, varios elementos requirieron corrección:
| Reclamación original | Corrección |
|---|---|
| Se analizaron exactamente 6 etiquetas OG | El analizador procesa 6 etiquetas OG, pero también analiza twitter:image, twitter:title, twitter:image:src, author, title, inLanguage, isAccessibleForFree, image (generic) y Schema.org JSON-LD. El total de etiquetas analizadas supera considerablemente las 6. |
EVERGREEN_VIBRANTes un tipo de clasificación de contenido | Es un nombre de paleta de colores de UI para XgadsContexttemas, junto con CANDY_VIBRANT, GLACIER_VIBRANT, LEMON_VIBRANT, etc. No es un tipo de contenido. |
engagement_time_mseces una señal de interacción específica de Discover | Es un parámetro estándar de Firebase Analytics (GA4) ( _eten la red), utilizado por todas las aplicaciones con Firebase Analytics. Mide la interacción a nivel de aplicación, no a nivel de artículo. |
freshness_delta_in_seconds/ staleness_in_hoursson métricas de contenido de Discover | En el código descompilado, estos aparecen en las métricas de calidad del aire/clima de Smartspace , no en las clases específicas de Discover. |
| Los depósitos de frescura (1_TO_7_DAYS, etc.) son específicos de Discover | Las cadenas de depósito existen, pero aparecen en un contexto de configuración de gestos , no en una clase Discover confirmada |
VISIBILITY_REPRESSED_COUNTERFACTUALes específico de Discover | Es un estado de registro de elementos visuales de todo Google que se comparte en toda la aplicación de Google (Asistente, Lens, Búsqueda, etc.). |
isCollectionHiddenFromEmberFeedSe trata del filtrado de feeds de Discover | Se trata de la pestaña Ember (una pestaña separada de descubrimiento de imágenes visuales en la aplicación de Google), no del feed Discover. |
PCTR_MODEL_TRIGGEREDConfirma un modelo Discover pCTR | No se encuentra en esta versión del SDK. Esto no significa que no exista. Puede estar en la configuración del servidor o en otra versión del SDK. |
| Las etiquetas OG son el objetivo principal del análisis | Los datos estructurados JSON-LD de Schema.org se verifican primero para determinar el título, el autor y la editorial. Las etiquetas OG son la alternativa. Estas etiquetas llevan mucho tiempo en uso. |
Nota metodológica#
Todos los hallazgos de Metehan Yeşilyurt han generado este análisis se derivan de la descompilación de 87,498 clases de Google App en 13 archivos DEX. De estas, el 95.5% estaban ofuscadas bajo un paquete p000/sin archivo de mapeo de ProGuard disponible.
La desofuscación se realizó mediante análisis de literales de cadena, rastreo de jerarquía de clases, extracción de endpoints de gRPC y reconstrucción de grafos mediante inyección de dependencias de Hilt. Cuando los hallazgos se confirman mediante coincidencias exactas de cadenas en el código fuente descompilado, se etiquetan como verificados. Cuando los hallazgos son inferencias basadas en convenciones de nomenclatura o proximidad de código, se indica.
No se accedió a los sistemas del servidor. Los modelos de clasificación del servidor, la asignación de experimentos y las etapas del pipeline pueden cambiar independientemente del cliente. Lo que podemos observar es la instrumentación; las preguntas que formula el sistema y las respuestas que registra, que revelan la arquitectura incluso cuando los parámetros cambian por debajo.
Infografía Metehan Yeşilyurt SEO experto:»Desvela las 9 fases del algoritmo de Google Discover»
Infografía Metehan Yeşilyurt SEO experto:»Desvela las 9 fases del algoritmo de Google Discover»
Fuentes
https://metehan.ai/blog/google-discover-architecture/
https://metehanai.substack.com/p/i-read-google-discovers-sdk-so-you
. Leer artículo completo en Frikipandi Metehan Yeşilyurt SEO experto:»Desvela las 9 fases del algoritmo de Google Discover».




{kind=link}
{kind=link}